前言
XPath是一门在XML文档中查找信息的语言。XPath用于在XML文档中通过元素和属性进行导航。XPath在爬取提取数据中非常好用,但是通过Chrome或者Firefox提取的XPath,经常会遇到在Python lxml库中提取不到数据,因为浏览器对不标准的HTML文档都有纠正功能,而lxml库不会,而从本地HTML文件中提取XPath又很不方便,所以既然XPath是从浏览器中提取的,那么通过selenium操纵Chrome提取XPath就准确很多,能省很多事。
安装依赖
pip安装selenium:
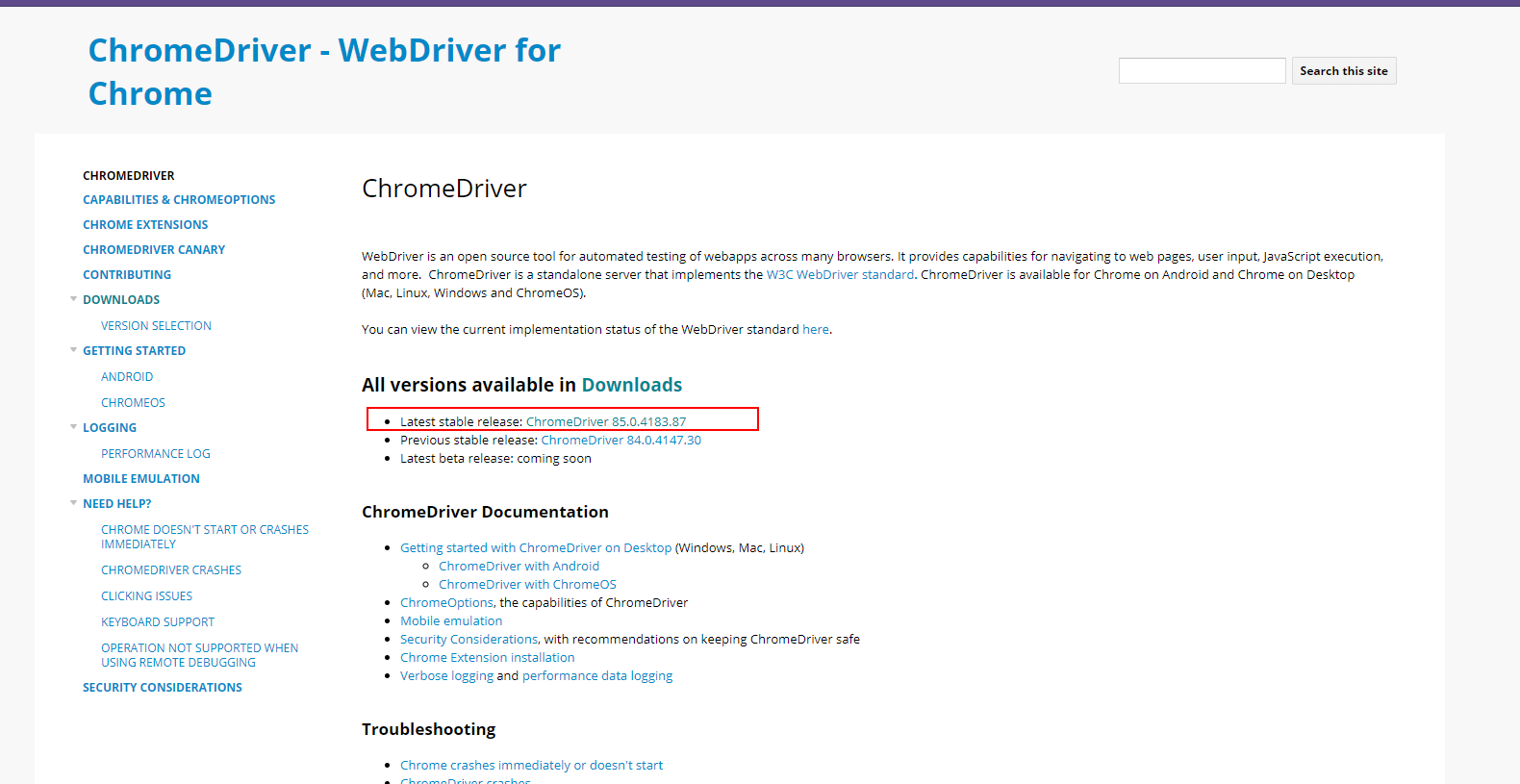
要使用selenium操纵Chrome,还需要下载ChromeDriver,点击下载(可能需要代理)对应版本的ChromeDriver:
![]()
下载后解压到项目文件夹内即可。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
from selenium import webdriver
def main():
filename = r'0830.html'
filepath = 'file://{}'.format(filename)
print(filepath)
options = webdriver.chrome.options.Options()
options.headless = True
driver = webdriver.Chrome(options=options)
driver.get(filepath)
cgbianhao = driver.find_element_by_xpath('//*[@id="two_pages_all"]/div[1]/div[2]/table[3]/tbody/tr[{}]/td[3]'.format(i)).text
cgname = driver.find_element_by_xpath('//*[@id="two_pages_all"]/div[1]/div[2]/table[3]/tbody/tr[{}]/td[4]'.format(i)).text
cgstarttime = driver.find_element_by_xpath('//*[@id="two_pages_all"]/div[1]/div[2]/table[3]/tbody/tr[{}]/td[5]'.format(i)).text
cgstopstime = driver.find_element_by_xpath('//*[@id="two_pages_all"]/div[1]/div[2]/table[3]/tbody/tr[{}]/td[6]'.format(i)).text
url_item = driver.find_element_by_xpath('//*[@id="two_pages_all"]/div[1]/div[2]/table[3]/tbody/tr[{}]/td[7]/a'.format(i)).get_attribute("onclick")
driver.close()
|
参考
ChromeDriver
为什么这个xpath在python中使用lxml失败?